



About BDDS
Introduction
In the digital age, Big Data and Data Science are transformative forces across industries. From healthcare and finance to e-commerce and governance, organizations are empowered by their ability to collect, process, and extract insights from massive datasets.
Together, they represent a fusion of:
- Data engineering
- Analytical modeling
- Artificial intelligence
These capabilities deliver actionable intelligence from the vast volumes of data generated every second.
What is Big Data?
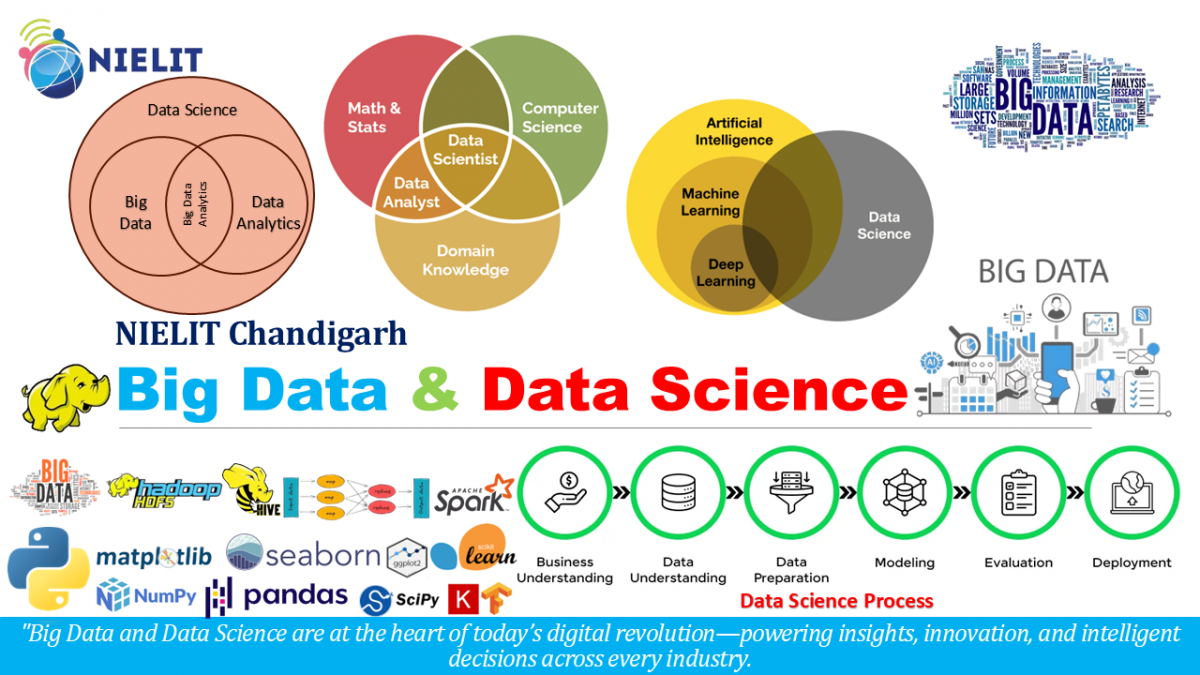
Big Data refers to extremely large and complex datasets that traditional data processing tools cannot manage efficiently. It is characterized by the 5 Vs:
- Volume – Massive quantities (terabytes to petabytes)
- Velocity – Real-time or rapid data generation
- Variety – Structured, semi-structured, and unstructured formats
- Veracity – Data uncertainty and quality issues
- Value – Extracting meaningful insights
Key Big Data Technologies:
- Hadoop Distributed File System (HDFS) – Scalable data storage
- MapReduce – Parallel data processing
- Apache Hive, Sqoop, Flume – Data ingestion and querying
- Apache Spark – In-memory computation and analytics
What is Data Science?
Data Science is an interdisciplinary field that extracts knowledge from data using:
- Statistics
- Computer Science
- Machine Learning (ML)
- Domain Expertise
- Data Engineering
Typical Data Science Lifecycle:
- Data Collection – From databases, APIs, sensors, etc.
- Data Cleaning & Preparation – Handle missing or inconsistent data
- Exploratory Data Analysis (EDA) – Visualization and pattern discovery
- Model Building – ML algorithms for predictions or classification
- Evaluation – Measure accuracy and performance
- Deployment – Integration into applications or systems
Popular Tools & Libraries:
- Python: Pandas, NumPy, Scikit-learn, Matplotlib, Seaborn
- TensorFlow / Keras – Deep learning
- SQL / NoSQL databases
- Jupyter / Google Colab – Interactive development environments
Why Learn Big Data & Data Science?
Organizations benefit from:
- Real-time analytics for better decisions
- Personalized customer experiences
- Operational automation and forecasting
- Competitive edge in a data-driven world
Career Opportunities:
- Data Scientist
- Machine Learning Engineer
- Big Data Analyst
- AI Researcher
- Business Intelligence Developer
Real-World Applications
|
Industry |
Applications |
|---|---|
|
Healthcare |
Predictive diagnostics, personalized medicine |
|
Finance |
Fraud detection, risk modeling, algo trading |
|
Retail |
Recommendation engines, inventory optimization |
|
Smart Cities |
Traffic prediction, resource optimization |
|
Agriculture |
Crop yield forecasting, disease detection |
|
Government |
Policy planning, e-governance, cybercrime analysis |
Technologies and Frameworks
Key tools that power Big Data & Data Science:
- Hadoop & Spark – Distributed processing
- Hive, Sqoop, Flume – Data ingestion and querying
- Python – Analytics and ML scripting
- MongoDB – NoSQL storage
- Scikit-learn – ML algorithms
- TensorFlow, PyTorch – Deep learning platforms
Program Formats
This training is offered in three flexible formats, blending theory and practice:
- Government Official Training – Basic: For absolute beginners
- Government Official Training – Advanced: For intermediate-level learners
- Bootcamp: Intensive and fast-track format
Each format includes labs, case studies, and a capstone project.
History & Background
The GOT (Government Official Training) and Bootcamp initiatives were introduced by the Ministry of Electronics and Information Technology (MeitY) under the FutureSkills PRIME Scheme. The goal: skill government officials and students for roles in Big Data and Data Science.
Since inception, graduates have transitioned into roles like:
- Data Analysts
- Big Data Developers
- Data Engineers
- Machine Learning Engineers
These programs are continuously updated to incorporate advancements in AI, ML, Cloud, and Data Analytics.
Program Objectives
- Understand foundational and advanced Big Data & Data Science concepts
- Analyze and visualize data for insights
- Gain hands-on skills with:
- Python, Hadoop, MongoDB, TensorFlow
- Solve real-world business problems using Big Data and ML
Expected Outcomes
Participants will be able to:
- Design and implement Big Data pipelines using Hadoop and Spark
- Perform data wrangling, visualization, and modeling in Python
- Apply ML and DL techniques to real scenarios
- Work with MongoDB, Hive, TensorFlow, and OpenAI APIs
- Present a capstone project using real datasets
Prerequisites
Participants should ideally have:
- Basic programming knowledge (preferably in Python or Java)
- Familiarity with Linux/Unix CLI
- Understanding of database systems (SQL/NoSQL)
Training Options & Curriculum
1. Government Official Training (GOT) – Basic (45 Hours)
Audience: Beginners
Modules:
- Big Data & Hadoop (12 hrs)
- DBMS Basics, Normalization
- HDFS, YARN, MapReduce
- Hive, ETL Concepts
- Working with Spark (3 hrs)
- Spark SQL, DataFrames
- Introduction to Scala
- Data Science with Python (15 hrs)
- Python Basics, Pandas, NumPy
- Stats & ML (Regression, Clustering)
- Data Visualization: Matplotlib, Seaborn
- Capstone Project (10 hrs)
2. Government Official Training (GOT) – Advanced (50 Hours)
Audience: Participants with basic prior experience
Modules:
- Big Data & Hadoop (8 hrs)
- Advanced Hadoop Ecosystem: Sqoop, Flume
- Spark Integration, Hive Projects, Web Scraping
- Working with Spark (7 hrs)
- Advanced DataFrames, Spark SQL
- Scala Programming
- Data Integration from APIs, DBs, Files
- NoSQL with MongoDB (5 hrs)
- CRUD Operations, Aggregation Pipeline
- Data Modeling
- Machine Learning (20 hrs)
- Supervised/Unsupervised Learning
- Scikit-learn, TensorFlow/Keras
- Model Tuning, Evaluation
- Capstone Project (10 hrs)
3. Bootcamp (40 Hours)
Target Audience: Fast-track learners, professionals, and students seeking intensive training in a short span.
Format: Hands-on, project-driven sessions with real-world scenarios.
Modules:
- Foundations of Big Data & Data Science (6 hrs)
- Overview of Big Data, 5Vs
- Data Science lifecycle and tools
- Use cases across industries
- Big Data & Hadoop Ecosystem (10 hrs)
- HDFS, YARN, MapReduce
- Apache Hive, Sqoop, Flume
- ETL Pipelines & Querying
- Apache Spark (5 hrs)
- Spark Core & Spark SQL
- DataFrames & RDDs
- Real-time data streaming basics
- Python for Data Science (8 hrs)
- Pandas, NumPy, Matplotlib, Seaborn
- Data Wrangling & EDA
- Basic Machine Learning with Scikit-learn
- Advanced Analytics & Deep Learning (6 hrs)
- Introduction to TensorFlow/Keras
- Regression, Classification
- Neural networks and model tuning
- Capstone Project (5 hrs)
- End-to-end project using real-world datasets
- Team-based or individual submission
- Presentation & evaluation
Learning Resources & References
Participants get access to:
- Lecture Slides, Code Notebooks, PDFs
- Lab exercises and curated datasets
Recommended Books:
- Hadoop: The Definitive Guide by Tom White
- Python for Data Analysis by Wes McKinney
- Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow by Aurélien Géron
Online References:
Mode of Delivery
- Live Instructor-Led Training (Online & Offline)
- Hands-on Labs and Assignments
- Interactive Quizzes, Discussions & Doubt-Clearing Sessions
- Capstone Project Reviews
Certification
Participants who complete the course and the capstone project will receive a:
Certificate of Course Completion from NIELIT Chandigarh
This certificate is:
- Recognized across government and private sectors
- Shareable on LinkedIn
- Credible for portfolio and job applications
Contact Us
The interested departments/students for upcoming batches can contact the following officers:
1. Deepak Wasan - Executive Director (E-mail) : dir-chandigarh@nielit.gov.in Executive Director, NIELIT Chandigarh 2. Anita Budhiraja - Scientist-E (M) : 01881-257009 (M) : 98159-88717 (E-mail) : a.budhiraja@nielit.gov.in Chief Investigator - Big Data & Data Science and Augmented and Virtual Reality 3. Dr. Sarwan Singh - Scientist-D (M) : 01881-257036 (M) : 98156-21657 (E-mail) : sarwan@nielit.gov.in Co-Chief Investigator - Augmented and Virtual Reality 4. Dr. Sharmistha Bhattacharjee - Scientist-D (M) : 01881-257009 (E-mail) : sharmisthab@nielit.gov.in Co-Chief Investigator - Big Data & Data Science